A proactive approach to monitoring and alerting is key to maintaining SQL Server performance. Monitoring provides real-time insight into the database’s health, resource consumption, and potential bottlenecks, while alerts enable prompt responses to issues before they impact users. SQL Server’s built-in tools, along with third-party solutions, offer effective ways to track key performance metrics, identify anomalies, and set up automated alerts to help stay ahead of performance problems.
Why Monitoring and Alerts Matter for Performance Optimization
Constantly changing workloads, hardware constraints, and system settings make SQL Server performance unpredictable. Monitoring helps identify trends and sudden deviations in performance, allowing for preventive measures or optimizations before they become critical. Alerts provide early warnings for issues like high CPU usage, long-running queries, or approaching storage limits, enabling quick intervention.
Key Monitoring and Alerting Best Practices for SQL Server
1. Define Key Performance Indicators (KPIs)
Before setting up a monitoring system, it’s essential to establish which metrics or KPIs best represent your SQL Server’s health and performance. These indicators should cover areas such as CPU, memory, disk usage, and specific SQL Server metrics.
- Best Practice:
- Track essential KPIs, including CPU utilization, memory usage, disk I/O, query wait times, and buffer cache hit ratio.
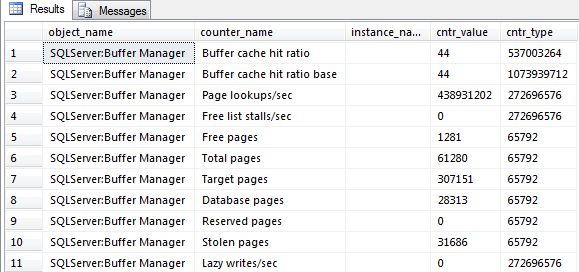
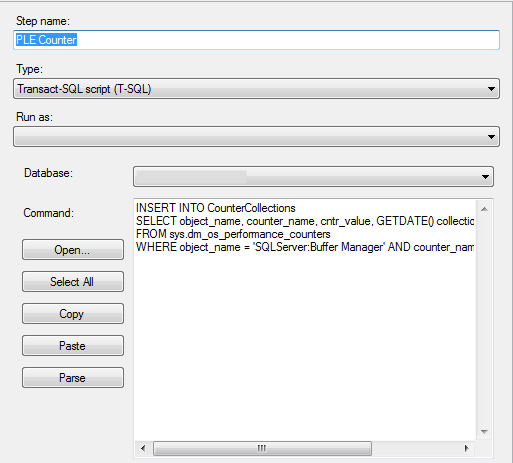
- For databases with heavy I/O demands, monitor page life expectancy (PLE), which shows how long a data page stays in the buffer cache.
- Keep an eye on log growth and transaction log space usage for signs of excessive logging, which may indicate poorly optimized queries or large transactions.
2. Use Dynamic Management Views (DMVs) for Real-Time Monitoring
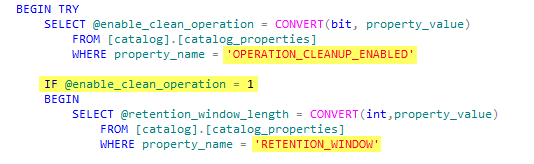
SQL Server’s Dynamic Management Views (DMVs) provide valuable insights into system performance by capturing real-time data on query execution, memory usage, and index efficiency. DMVs are essential for identifying specific issues that require immediate attention.
- Best Practice:
- Use DMVs like
sys.dm_exec_query_statsto identify long-running or resource-intensive queries andsys.dm_os_wait_statsto understand wait types and locate bottlenecks. - Regularly analyze index usage using
sys.dm_db_index_usage_statsto determine which indexes are frequently used and which are candidates for removal. - Automate DMV queries to gather data at regular intervals and retain historical performance data for trend analysis.
- Use DMVs like
3. Set Up SQL Server Performance Alerts
SQL Server Agent allows you to configure alerts for specific events, such as high CPU or memory usage, job failures, or database connection issues. Alerts can be sent via email or logged to a table for review.
- Best Practice:
- Configure alerts for CPU usage exceeding 80%, memory pressure warnings, blocked processes, disk space thresholds, and failed SQL Agent jobs.
- Set up alerts for critical wait types, like
PAGEIOLATCHfor disk-related bottlenecks orLCK_M_*for blocking and locking issues. - Ensure that alerts provide actionable information and avoid alert fatigue by fine-tuning alert thresholds and focusing on the most critical metrics.
4. Utilize SQL Server Extended Events for Detailed Diagnostics
SQL Server Extended Events offers a lightweight, customizable framework for tracking detailed performance data. Extended Events can capture detailed information on query execution, deadlocks, wait times, and system-level events without a significant performance impact.
- Best Practice:
- Create custom Extended Events sessions to capture specific performance issues, like long-running queries or high wait times.
- Use Extended Events to monitor deadlocks and capture the SQL text, session ID, and resources involved for troubleshooting.
- Archive Extended Events data for historical analysis, as this information is valuable for identifying recurring issues or performance trends.
5. Implement Database Monitoring Tools
In addition to built-in tools, various third-party solutions (e.g., SolarWinds, Redgate SQL Monitor, and Idera SQL Diagnostic Manager) provide advanced monitoring and alerting capabilities for SQL Server. These tools often offer features like dashboards, reporting, automated analysis, and recommendations.
- Best Practice:
- Choose a tool that provides real-time monitoring, historical trend analysis, and robust alerting based on your organization’s needs and budget.
- Look for monitoring solutions that include visualizations for easy diagnosis of issues like query bottlenecks or resource contention.
- Use third-party tools that support customizable alerts and integrate with incident management systems to streamline response workflows.
6. Monitor Query Performance
Query performance is one of the most significant factors affecting SQL Server’s efficiency. Using monitoring to detect slow or inefficient queries helps with timely tuning and optimization.
- Best Practice:
- Regularly monitor query execution times, CPU and I/O usage for top-running queries, and identify queries that are consistently resource-intensive.
- Use Query Store in SQL Server to track query plans and execution statistics, making it easier to identify performance regressions after schema changes or updates.
- Set alerts for queries running above a specific threshold or those with high execution counts that may indicate inefficiencies.
7. Monitor Tempdb Usage
Since tempdb is frequently used for temporary storage, sorting, and intermediate query results, high tempdb usage or contention can degrade performance. Monitoring tempdb ensures that it has adequate space and can handle temporary object creation demands.
- Best Practice:
- Monitor tempdb space usage using DMVs like
sys.dm_db_task_space_usageandsys.dm_db_session_space_usage. - Configure alerts for tempdb growth or high utilization, which could indicate inefficient query processing or excessive use of temporary tables.
- Use monitoring to detect contention on tempdb, especially on system pages like PFS, GAM, and SGAM, and address it by adding more data files.
- Monitor tempdb space usage using DMVs like
8. Create Custom Alerts for Resource-Specific Metrics
Different applications and workloads may have unique performance demands, so SQL Server supports custom alerts tailored to your specific environment. Custom alerts allow more granular monitoring of resource-specific metrics, such as long lock times or unusually high I/O operations.
- Best Practice:
- Set custom alerts for lock escalation, deadlocks, and blocking sessions that exceed specified thresholds.
- Create alerts for excessive logins, failed login attempts, or unusual access patterns for security monitoring.
- Use custom alerts for sudden changes in query execution plans, which may indicate suboptimal plan choices or regressions due to outdated statistics.
9. Enable Automated Responses for Critical Alerts
Responding to alerts manually can be time-consuming, so SQL Server Agent allows you to define responses to specific alerts. Automated responses can include restarting services, running scripts, or adjusting resources temporarily to prevent further degradation.
- Best Practice:
- For critical alerts, configure automated responses such as restarting SQL Server services, clearing cache, or scaling up cloud resources if available.
- Set automated scripts to collect additional diagnostics when an alert is triggered, helping capture valuable data for post-incident analysis.
- Use escalation protocols to ensure that critical alerts that require manual intervention are immediately directed to the right team members.
10. Log Monitoring for Long-Term Insights
Long-term log monitoring is useful for understanding performance trends, identifying recurring issues, and tracking the impact of changes over time. SQL Server’s Error Log, Windows Event Log, and system_health Extended Events session are valuable sources of diagnostic information.
- Best Practice:
- Regularly review SQL Server Error Logs for messages related to I/O warnings, login failures, and deadlocks, and establish alerts for critical log entries.
- Monitor Windows Event Logs for system-level alerts related to hardware failures, memory issues, or networking problems that could affect SQL Server performance.
- Use log aggregation tools like Elasticsearch, Splunk, or Azure Monitor to centralize and analyze logs, allowing for faster identification of trends and potential issues.
Conclusion
Proactive monitoring and alerting ensure that SQL Server remains resilient, responsive, and optimized for performance over time. By defining KPIs, setting up automated alerts, monitoring query and resource usage, and utilizing both built-in and third-party tools, you can identify performance issues early and take corrective actions before they impact end-users. Implementing a structured monitoring and alerting strategy is essential for long-term SQL Server performance optimization and helps your team stay one step ahead of potential bottlenecks.