We’ve all heard about database/index fragmentation (and if you haven’t, continue reading), but what is it? Is it an issue? How do I know if it resides in my database? How do I fix it? These questions could be a tip all in itself, but I’ll try to give you an idea of each in this post.
Without going into a lot of detail, SQL Server stores data on 8KB pages. When we insert data into a table, SQL Server will allocate one page to store that data unless the data inserted is more than 8KB in which it would span multiple pages. Each page is assigned to one table. If we create 10 tables then we’ll have 10 different pages.
As you insert data into a table, the data will go to the transaction log file first. The transaction log file is a sequential record meaning as you insert, update, and delete records the log will record these transactions from start to finish. The data file on the other hand is not sequential. The log file will flush the data to the data file creating pages all over the place.
Now that we have an idea of how data is stored, what does this have to do with fragmentation?
There are two types of fragmentation: Internal Fragmentation and External Fragmentation.
SQL Server Internal Fragmentation
SQL Server Internal Fragmentation is caused by pages that have too much free space. Let’s pretend at the beginning of the day we have a table with 40 pages that are 100% full, but by the end of the day we have a table with 50 pages that are only 80% full because of various delete and insert statements throughout the day. This causes an issue because now when we need to read from this table we have to scan 50 pages instead of 40 which should may result in a decrease in performance. Let’s see a quick and dirty example.
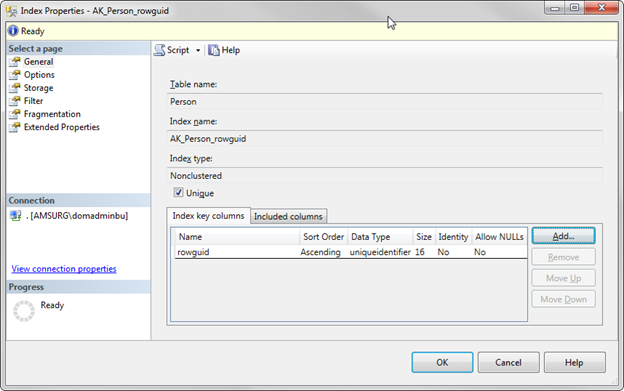
Let’s say I have the following table with a Primary Key and a non-clustered index on FirstName and LastName:
 I’ll talk about ways to analyze fragmentation later in this tip, but for now we can right click on the index, click Properties, and Fragmentation to see fragmentation and page fullness. This is a brand new index so it’s at 0% fragmentation.
I’ll talk about ways to analyze fragmentation later in this tip, but for now we can right click on the index, click Properties, and Fragmentation to see fragmentation and page fullness. This is a brand new index so it’s at 0% fragmentation.