Database design is a critical component of SQL Server performance. A well-designed database not only ensures efficient data storage but also optimizes query execution and minimizes maintenance overhead. Poorly designed databases can lead to issues like slow queries, increased I/O, and inefficient use of memory and CPU resources. By focusing on best practices during the design phase, you can lay a strong foundation that supports scalability, reliability, and performance.
The Impact of Database Design on Performance
A database’s architecture affects how SQL Server retrieves, processes, and stores data. Good database design reduces redundancy, minimizes the need for expensive joins or subqueries, and ensures that the system can efficiently handle growing datasets. It’s easier to address performance concerns in the design phase than to attempt optimization after the database is in production.
Best Practices for Database Design
1. Normalization vs. Denormalization
Normalization is the process of structuring a relational database to minimize data redundancy and dependency. It organizes data into separate tables based on logical relationships, ensuring that each table contains only relevant data.
- Benefits of Normalization:
- Reduces redundant data, which saves storage space and improves data consistency.
- Simplifies updates and deletions, reducing the chance of anomalies.
However, excessive normalization can lead to performance issues by increasing the number of joins required in queries. This is where denormalization comes in—a strategic process where certain normalized tables are combined to reduce the need for joins in performance-critical queries.
- Best Practice:
- Start with normalization (3rd Normal Form is often a good starting point), then selectively denormalize where performance gains justify the added redundancy. For example, when querying data frequently involves multiple joins, denormalize to reduce the join overhead.
- Balance between normalization and denormalization depending on the nature of the workload, ensuring that performance isn’t compromised for the sake of maintaining pure data integrity.
2. Choose Appropriate Data Types
Choosing the right data types for each column is crucial for both performance and storage efficiency. Using larger data types than necessary wastes memory and increases I/O, while inappropriate data types can result in slower query execution.
- Best Practice:
- Use the smallest data type that can accommodate the data. For example, if a column only needs to store numbers between 1 and 100, use
TINYINT(1 byte) rather thanINT(4 bytes). - For string data, use
VARCHAR(variable-length) instead ofCHAR(fixed-length) to save space. For columns with predictable length, such as country codes, useCHARwith a defined length. - Avoid overusing
NVARCHARunless absolutely necessary (e.g., for multi-language support with Unicode). Non-Unicode data types likeVARCHARconsume less space. - Match data types in joins and filters: If you use mismatched data types in queries, SQL Server may need to perform implicit conversions, which add overhead and slow down execution.
- Use the smallest data type that can accommodate the data. For example, if a column only needs to store numbers between 1 and 100, use
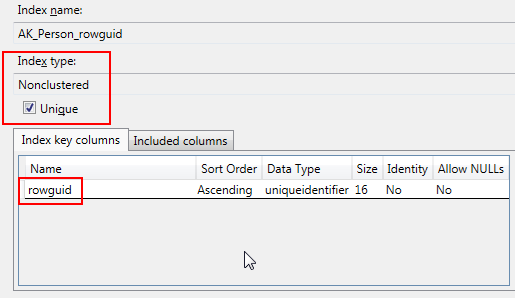
3. Primary Keys and Foreign Keys
Primary keys uniquely identify records in a table and are critical for data integrity and indexing. SQL Server automatically creates a clustered index on the primary key by default, which affects how data is stored and retrieved.
Foreign keys enforce relationships between tables, ensuring referential integrity. Although they don’t directly improve performance, they prevent orphaned records and ensure data consistency.
- Best Practice:
- Choose the right primary key: Use an integer-based key whenever possible, as smaller data types are faster to index and join. Avoid composite or complex keys if they aren’t necessary.
- Use foreign keys: Even though foreign key constraints don’t directly improve performance, they ensure database integrity, which is crucial for long-term stability and reducing potential performance-killing errors.
4. Index Design
Indexes are critical for optimizing query performance, but they must be carefully designed to avoid performance degradation due to maintenance overhead or excessive index usage.
- Best Practice:
- Create clustered indexes on frequently queried columns that define the logical order of the table. Generally, the primary key should be the clustered index unless there’s a more frequently queried column.
- Use non-clustered indexes to speed up search queries, especially on columns frequently used in
WHERE,JOIN, orORDER BYclauses. - Avoid over-indexing: Creating too many indexes can lead to increased maintenance costs (e.g., during
INSERT,UPDATE, andDELETEoperations) and longer execution times. Be selective about which columns to index. - Regularly analyze index usage with SQL Server’s Dynamic Management Views (DMVs) to identify unused or underutilized indexes that can be removed to improve performance.
5. Partitioning for Large Tables
Partitioning allows you to split large tables into smaller, more manageable chunks. SQL Server’s table partitioning feature distributes table data across multiple partitions, based on a defined column (such as a date). This helps SQL Server read smaller portions of the table during queries, leading to improved performance, especially for large datasets.
- Best Practice:
- Use partitioning to improve query performance on large tables, especially when queries frequently filter by the partition key (such as
OrderDateorTransactionDate). - Partition by range for time-based data to enable SQL Server to prune irrelevant partitions during queries, reducing I/O.
- Balance the number of partitions; too many small partitions can lead to overhead, while too few may not improve performance significantly.
- Use partitioning to improve query performance on large tables, especially when queries frequently filter by the partition key (such as
6. Schema and Object Naming Conventions
A clear and consistent naming convention for database objects (tables, indexes, stored procedures) helps maintain organization and ease troubleshooting.
- Best Practice:
- Use descriptive names for tables and columns that clearly describe their purpose (e.g.,
CustomerAddressorOrderDetails). Avoid ambiguous or overly abbreviated names. - Group related objects into schemas to simplify permissions management and improve organization. For example, use a schema like
Salesfor all objects related to sales data.
- Use descriptive names for tables and columns that clearly describe their purpose (e.g.,
7. Avoid Overly Complex Queries
Poor database design often forces developers to write complex queries, including multiple joins, subqueries, and scalar functions, which can severely degrade performance.
- Best Practice:
- Simplify queries by using appropriate indexes and database design techniques like denormalization where necessary.
- Avoid using correlated subqueries that run for each row in the outer query, as they can result in extremely poor performance. Instead, use joins or common table expressions (CTEs) when possible.
- Minimize scalar functions in
WHEREclauses orSELECTstatements. Scalar functions can slow down queries because they execute row by row. Inline table-valued functions are a better alternative when complex logic is required.
8. Consider Data Archiving and Purging
Large databases that store data indefinitely can slow down performance over time. By regularly archiving or purging old or irrelevant data, you can reduce the size of your active dataset and improve query performance.
- Best Practice:
- Implement a data retention policy to archive or delete old data that’s no longer needed. This reduces the overall size of tables and indexes, leading to faster queries and less disk space consumption.
- For large datasets that need to be retained for compliance reasons, consider using partitioning or moving older data to a separate archive database.
Conclusion
Solid database design lays the groundwork for optimal SQL Server performance. By following best practices like appropriate normalization, thoughtful indexing, partitioning for large datasets, and the strategic use of primary/foreign keys, you can ensure that your database not only performs well today but remains scalable and maintainable as your data grows. When combined with ongoing query tuning and regular database maintenance, strong design principles provide the foundation for long-term success in SQL Server environments.