If you’re in the tech field you’ve probably heard the buzz around ChatGPT and Artificial Intelligence.
ChatGPT is a pre-trained language model developed by OpenAI. It uses deep learning techniques, specifically a transformer neural network architecture, to generate human-like text. It can be fine-tuned on specific tasks such as language translation, question answering, and text summarization. ChatGPT can be used to generate a wide range of text, including conversation, news articles, stories, and more. Because it is pre-trained on a large corpus of text, it can generate text that is often indistinguishable from text written by a human.
To preview ChatGPT, shoot over to https://openai.com, create a login and you can try it for free (at the time this post was written).
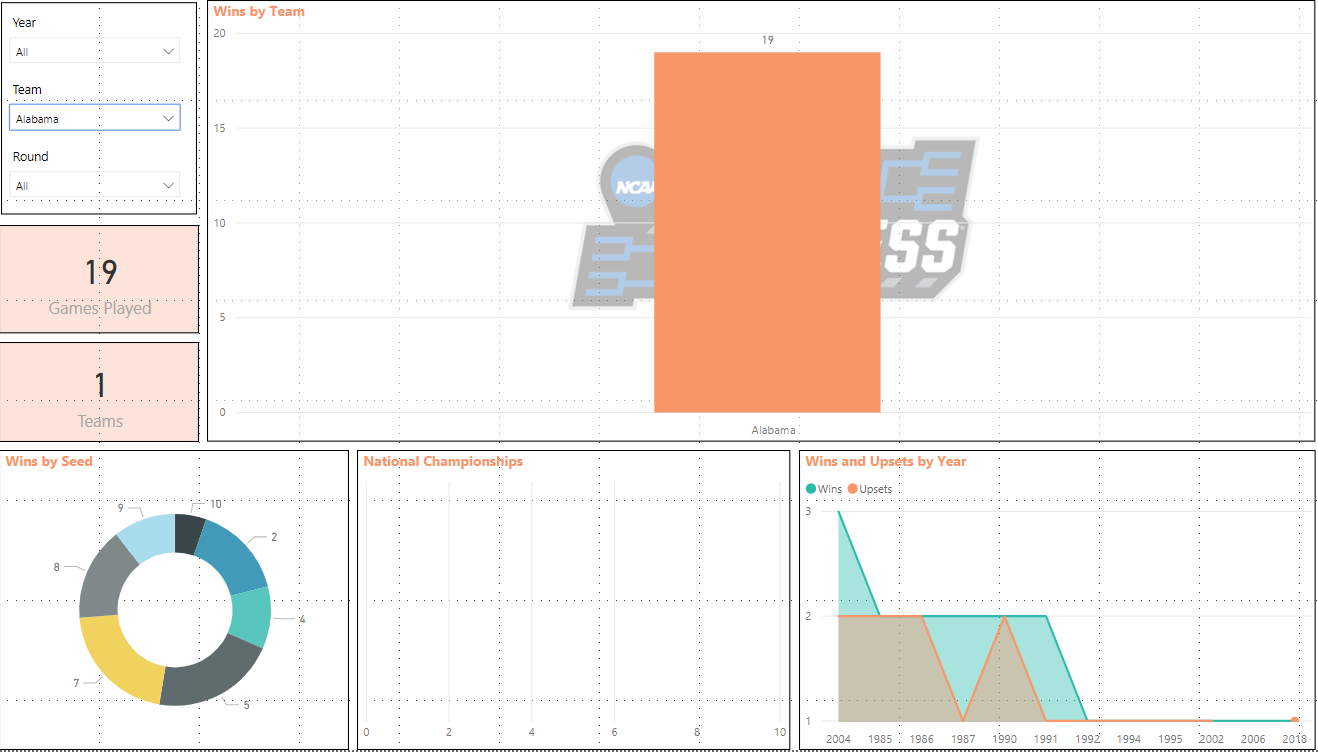
For this post, since I’m a DBA, I want to test how it performs when I give it questions about SQL statements.
So let’s start! I asked the following question:
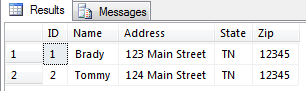
“How can ChatGPT be used to learn TSQL?”
And here’s a great response:
ChatGPT can be used to learn TSQL in several ways:
You can use ChatGPT to generate TSQL code snippets and queries based on natural language prompts. For example, you can ask ChatGPT to "generate a TSQL query to select all columns from a table named 'customers'" and it will respond with the appropriate TSQL code.You can also use ChatGPT to explain TSQL concepts and provide examples. For example, you can ask ChatGPT to "explain how to use the JOIN clause in TSQL" and it will provide a detailed explanation and examples of how to use the JOIN clause in TSQL.You can also train ChatGPT model on TSQL text data and fine-tune the model for generating TSQL queries, this way you can generate more accurate and complex TSQL queries.You can use ChatGPT as a code completion tool to assist you in writing TSQL code.
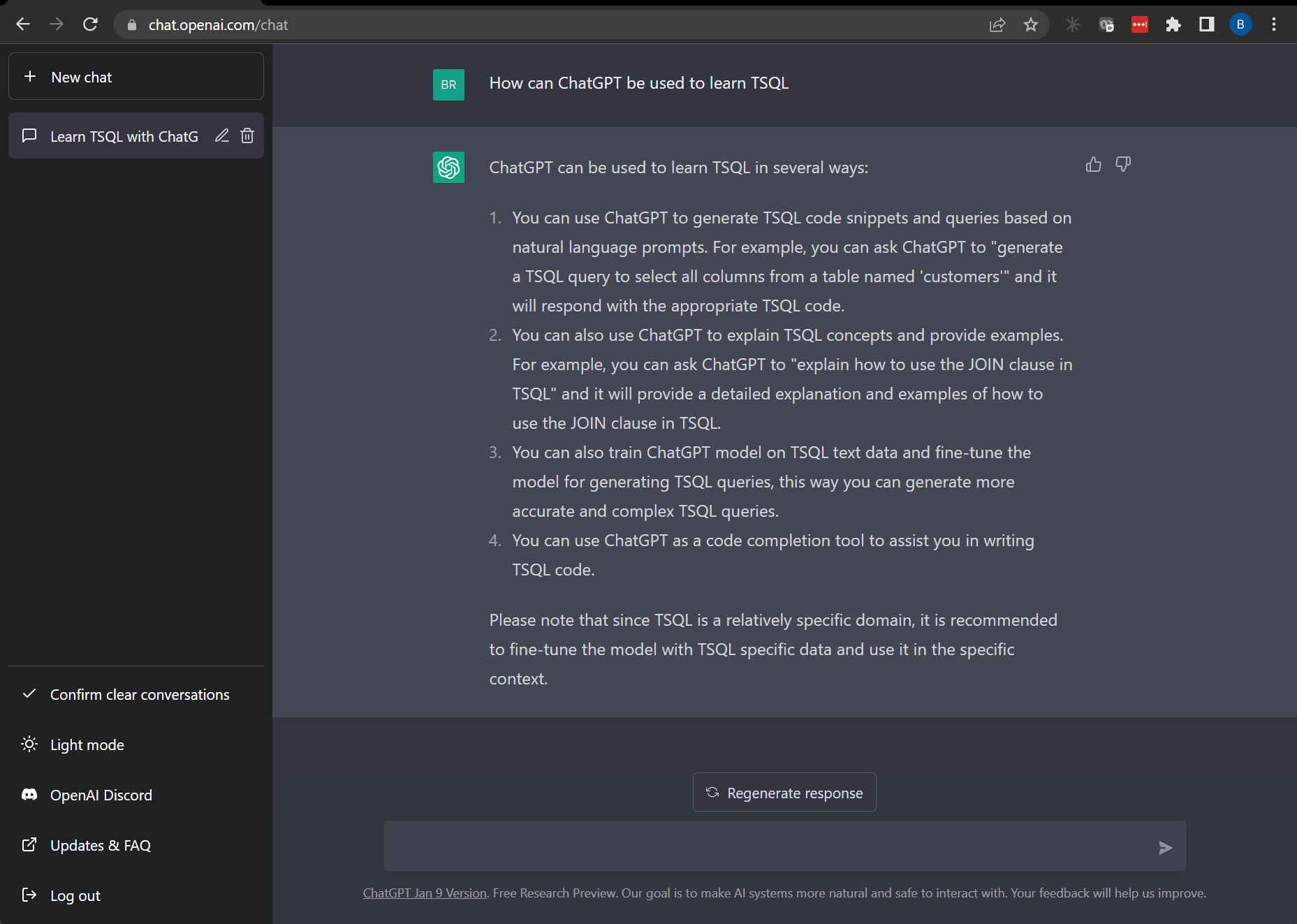
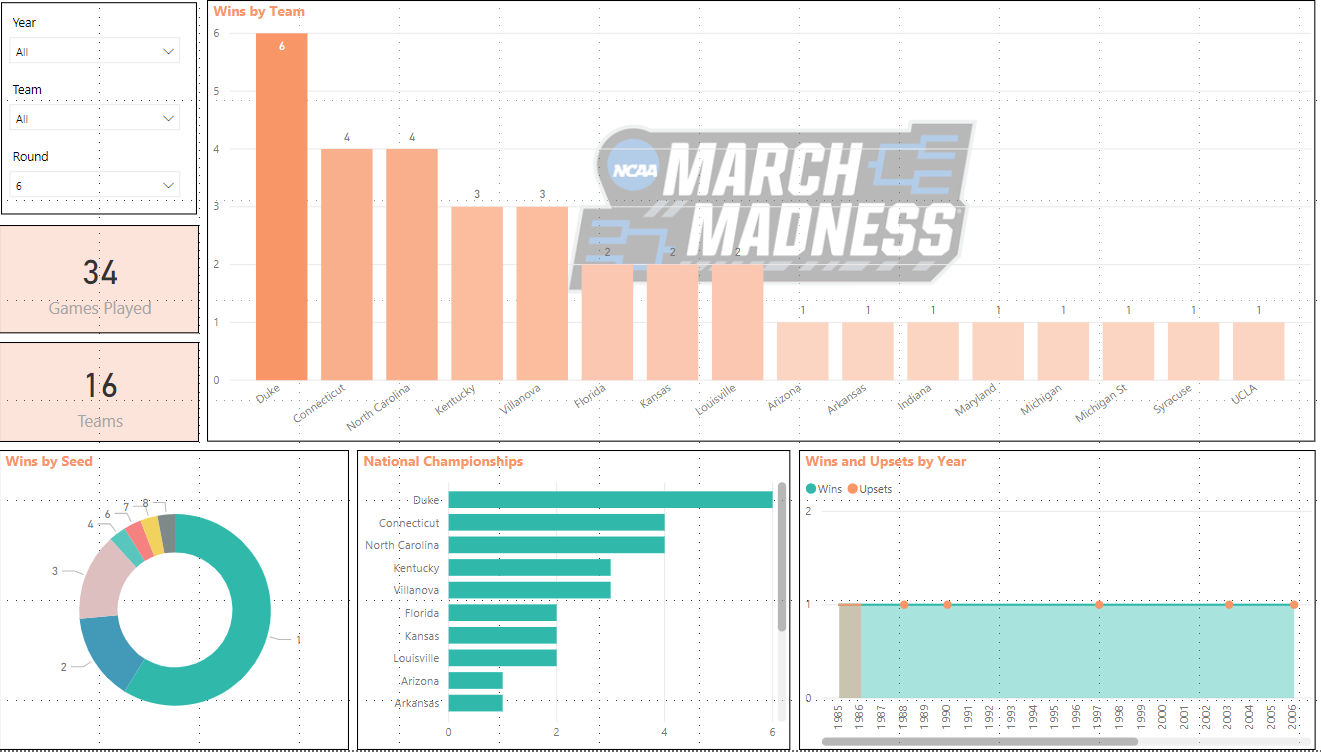
Not a bad start. Let’s see if it can create a database.
“Can you write SQL code to create a SQL database named AI?”
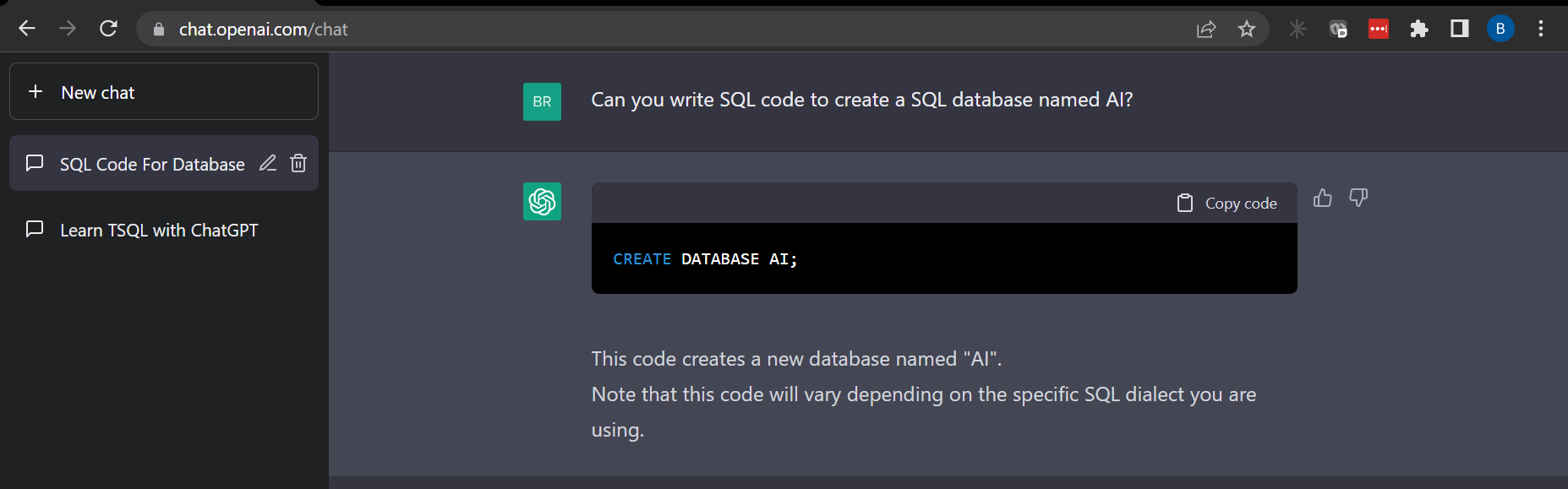
Look correct. Let’s test in SQL Management Studio.
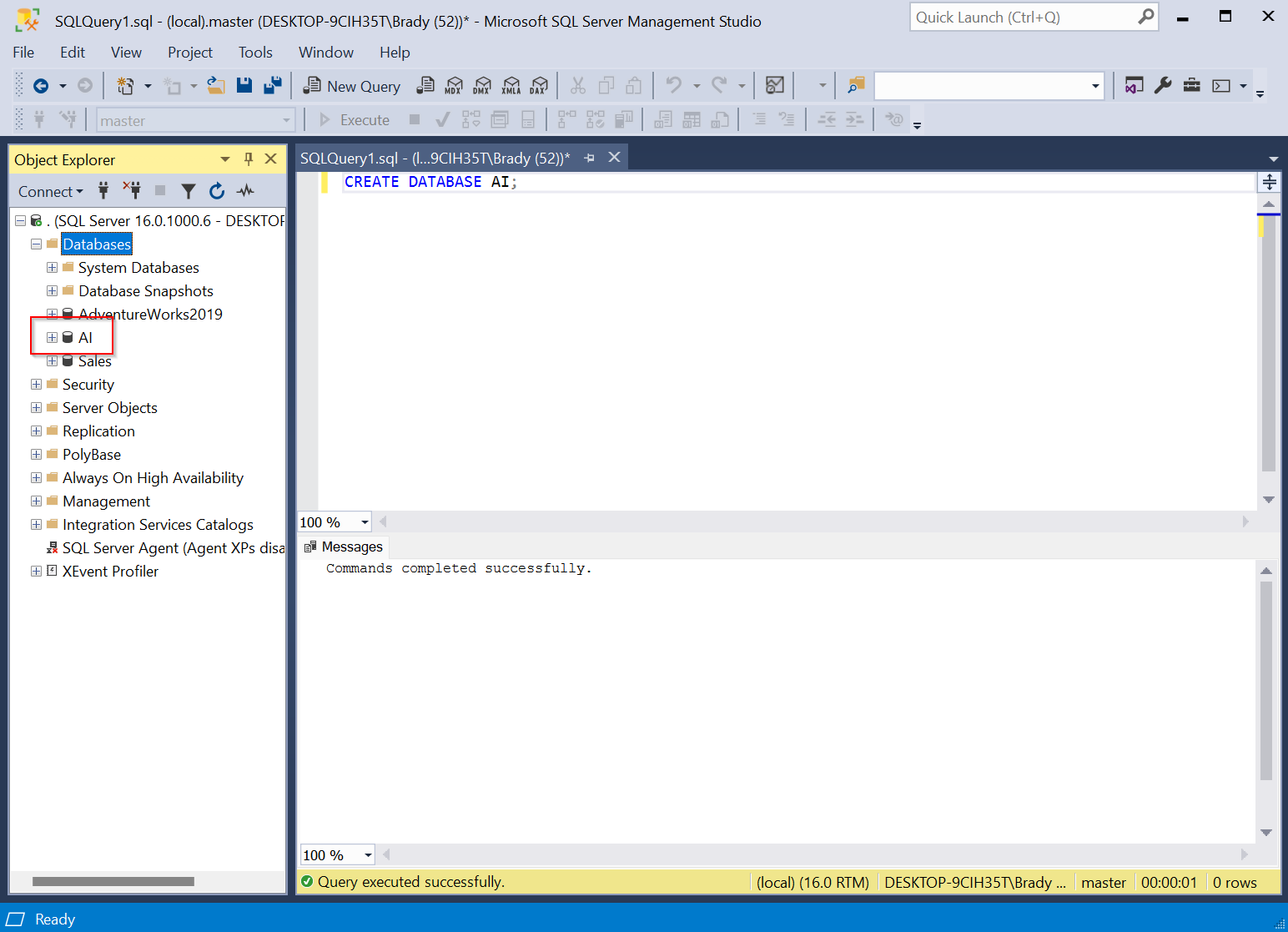
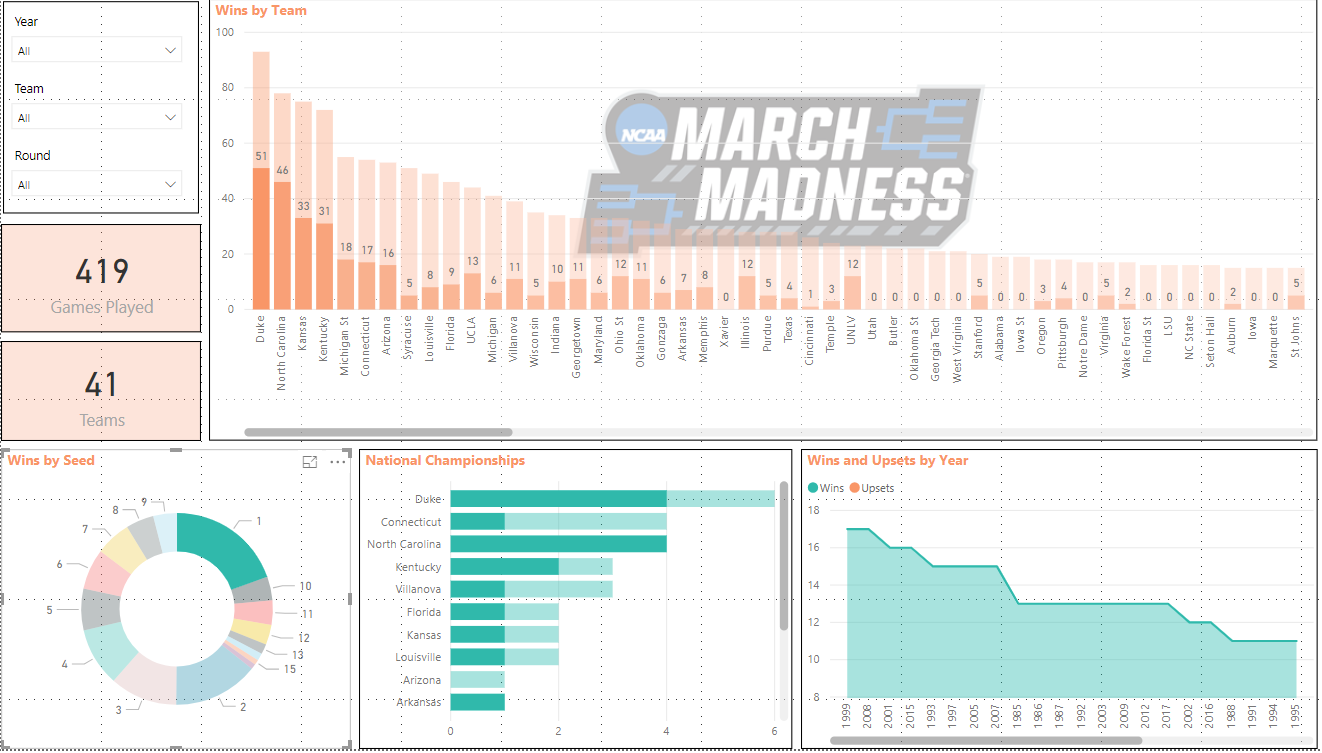
OK, OK, that was too easy ChatGPT. Let’s see if it can create a table in our new database and insert some dummy data.
“Can you write SQL code to create a table called Orders in my AI database and populate with some test data?”
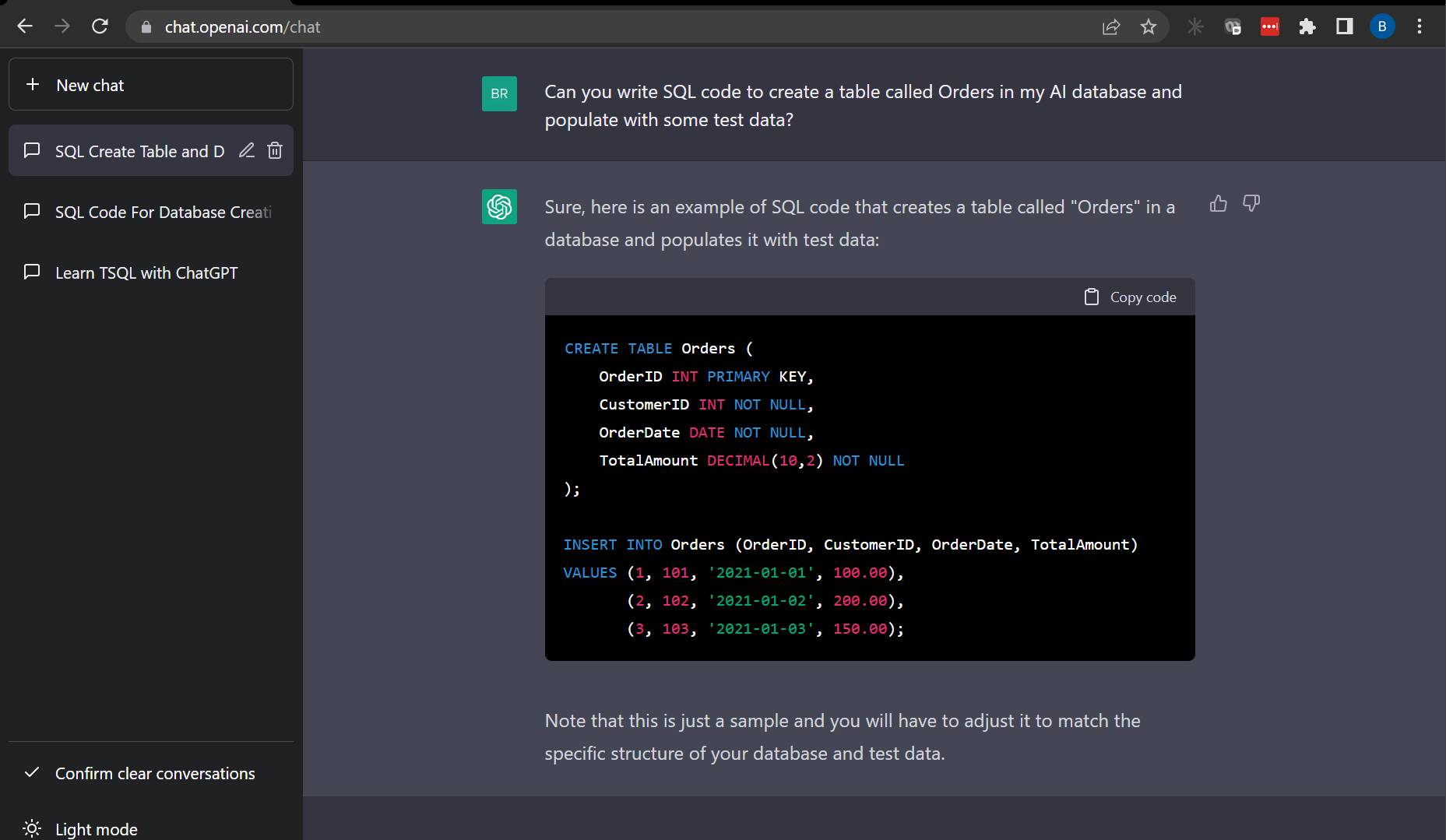
Let’s test the code.
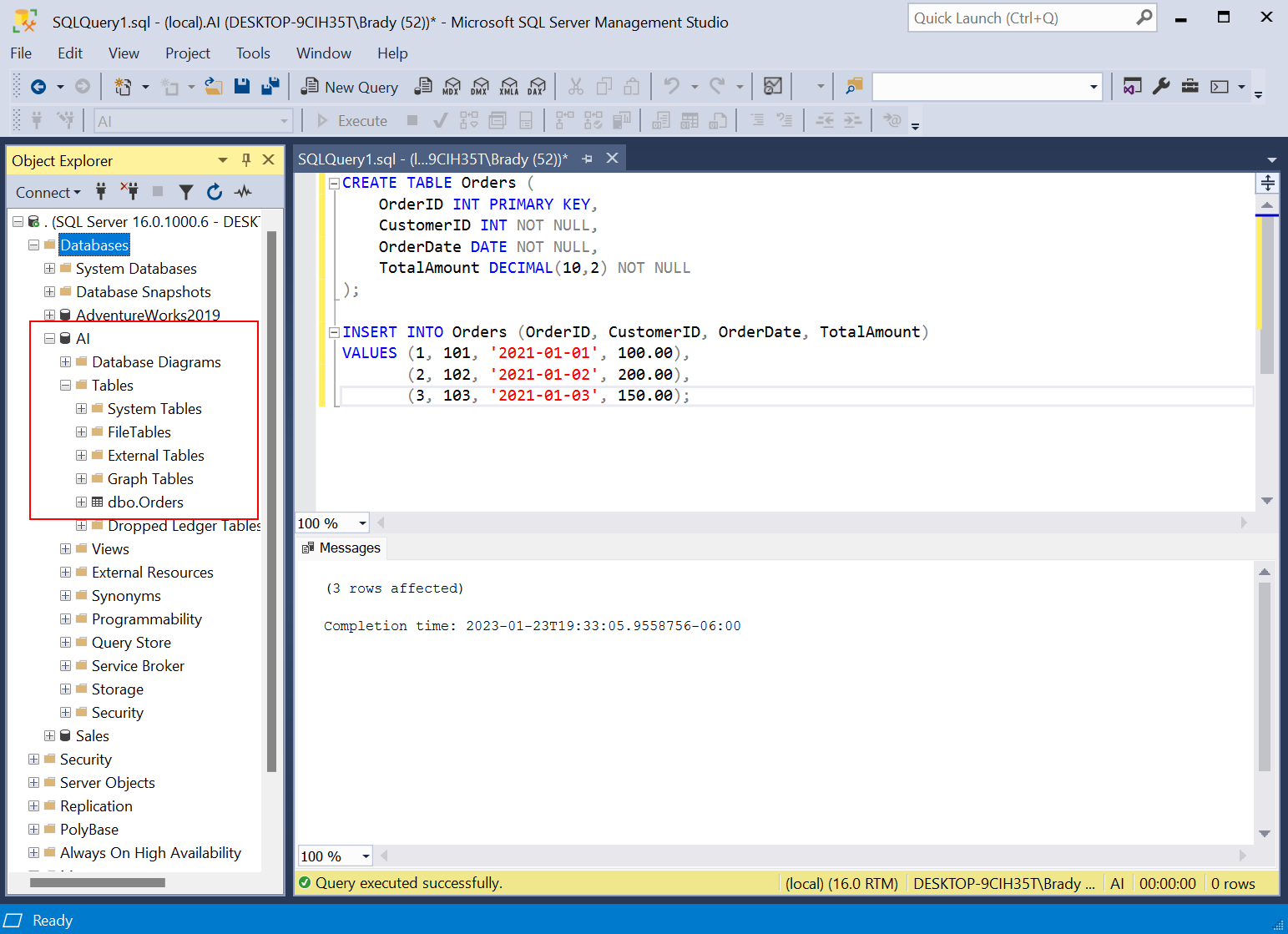
Looks good. How about a basic SELECT statement?
“Can you write SQL code to give me all data from my Orders table?”
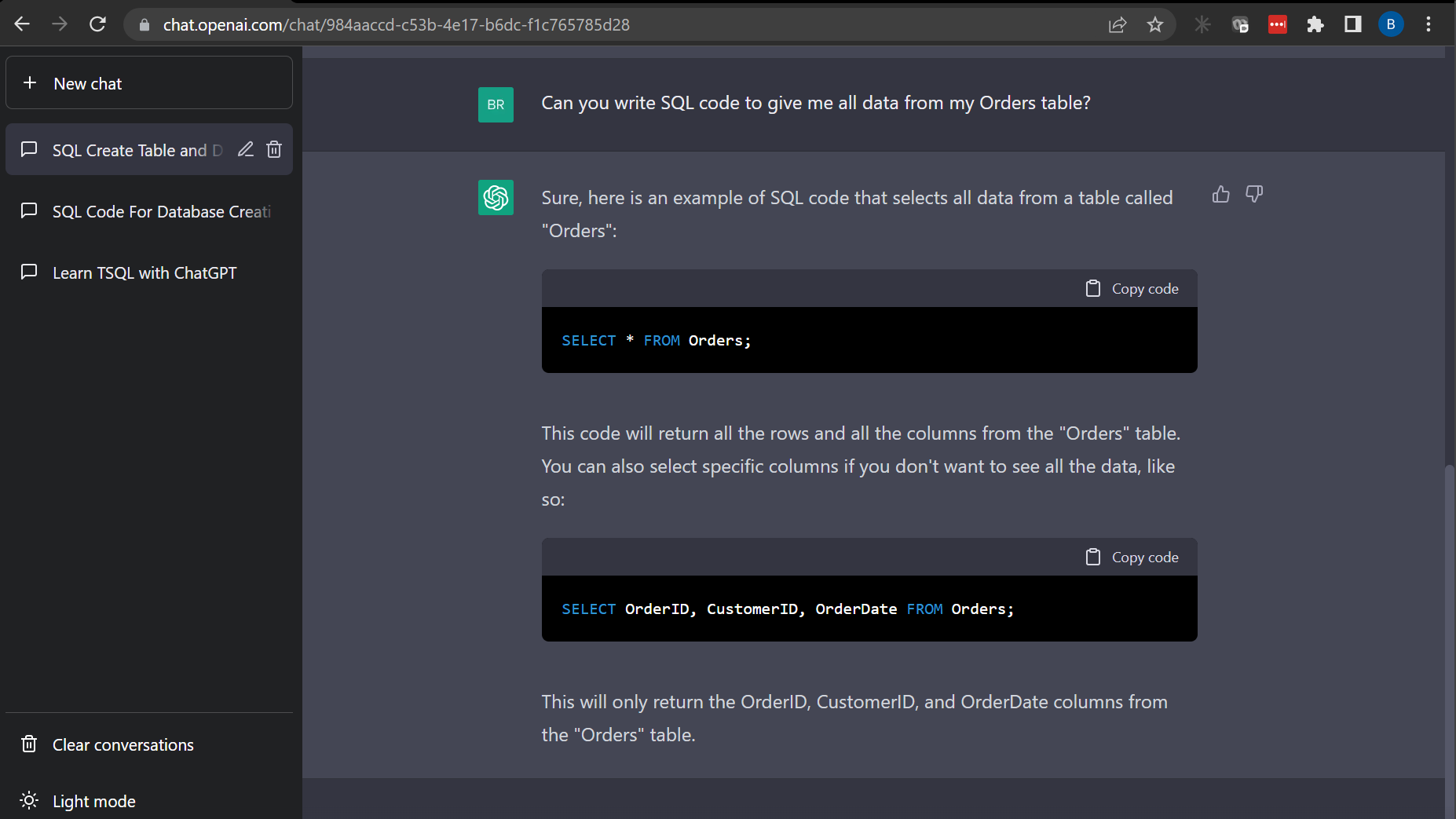
Again, looks good. It even goes as far as explaining it and giving an example by only selecting specific rows. This is great for learning.
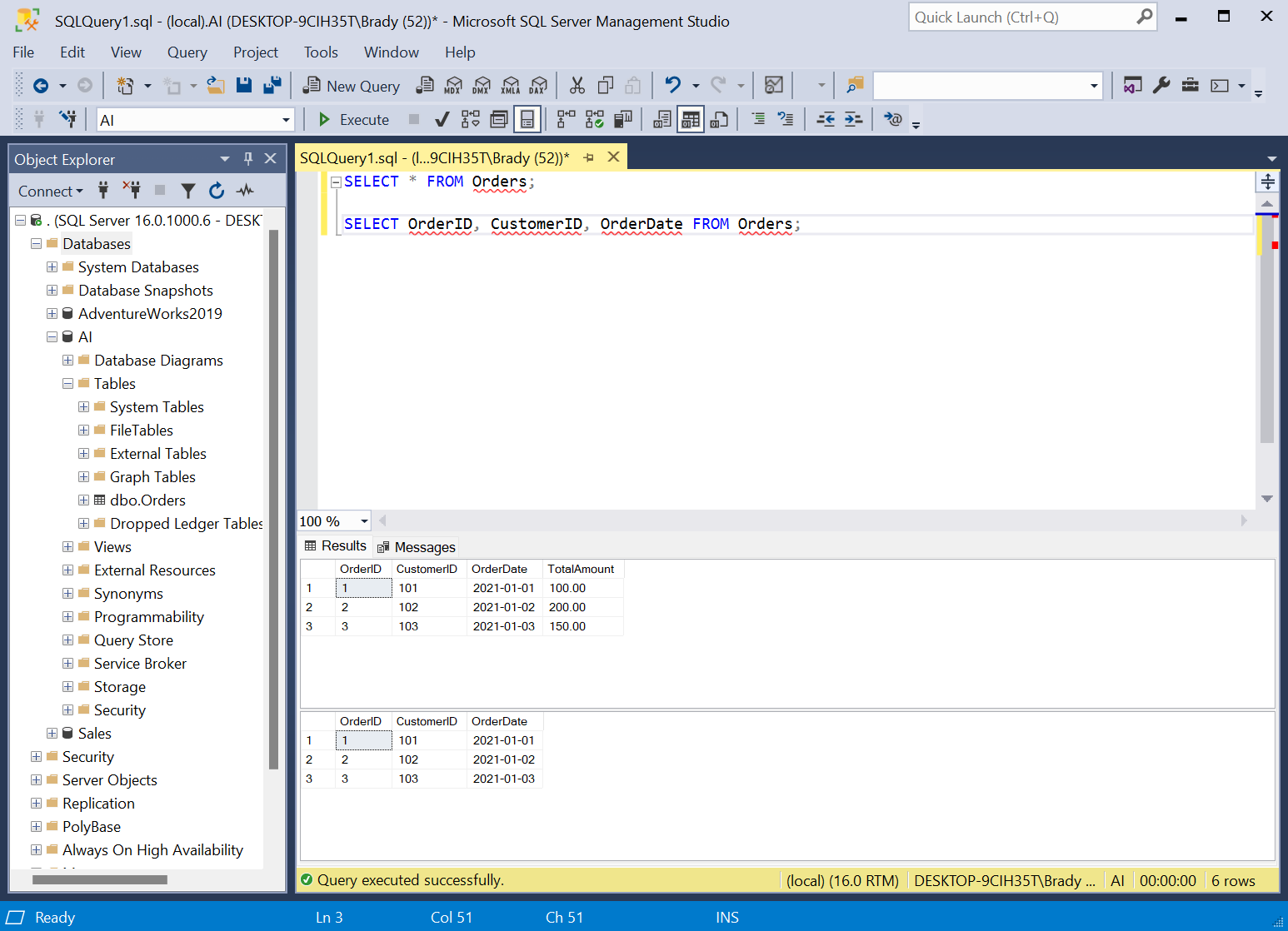
Let’s see if it can create an aggregate query.
“Can you write SQL code to give me the Customer that has the highest TotalAmount from the Orders table?”
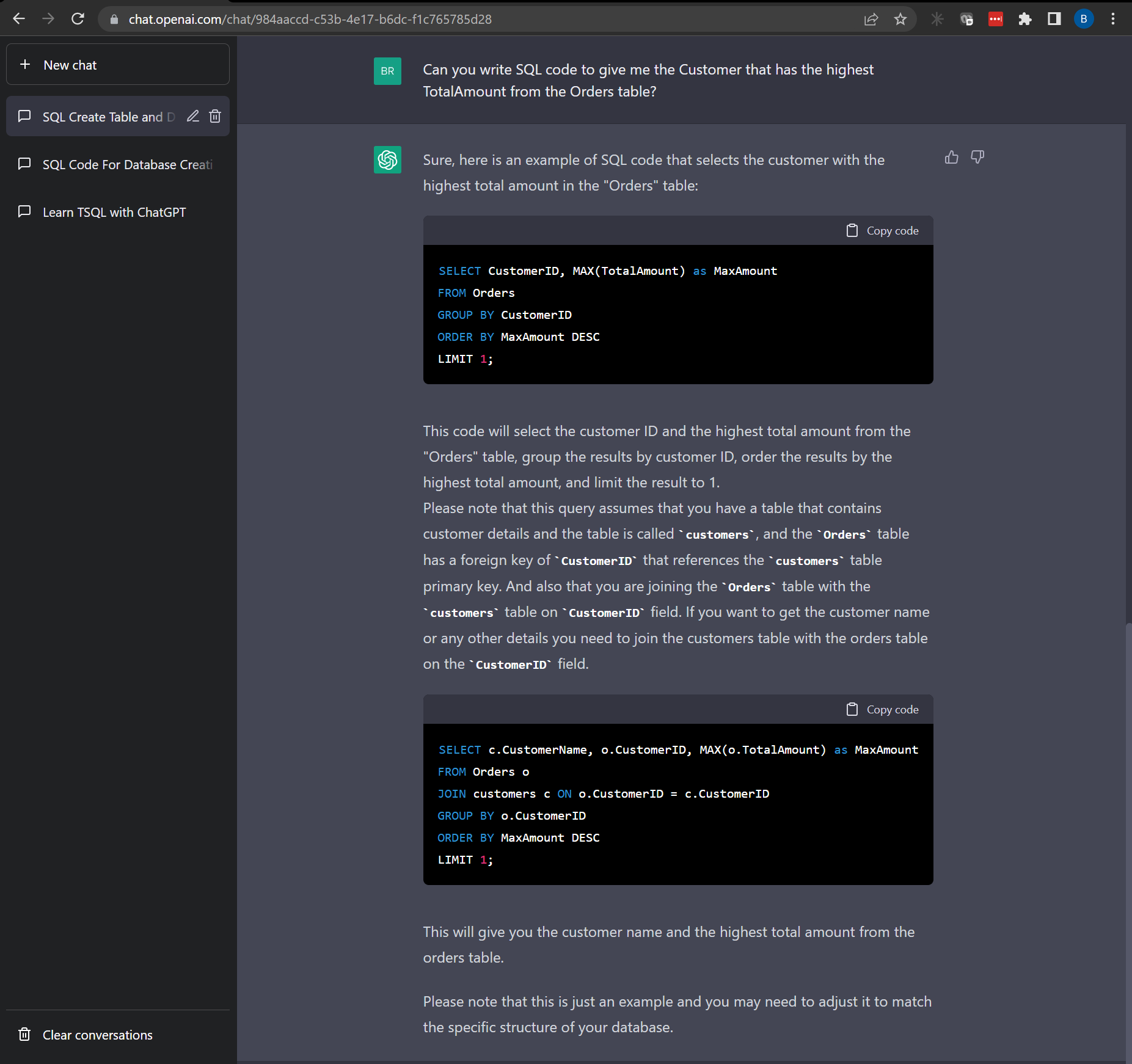
From my question, I was hoping for something a little different, but I can’t get mad at the results. The query uses LIMIT 1 instead of SELECT TOP 1 which would work in MySQL, but doesn’t exist in SQL Server. It was really close though and it even gives me an example and explanation of how this would be used in a JOIN.
Let’s be more specific. If I change the question to specify SQL Server:
“Can you write SQL code to give me the Customer that has the highest TotalAmount from the Orders table in SQL Server?”
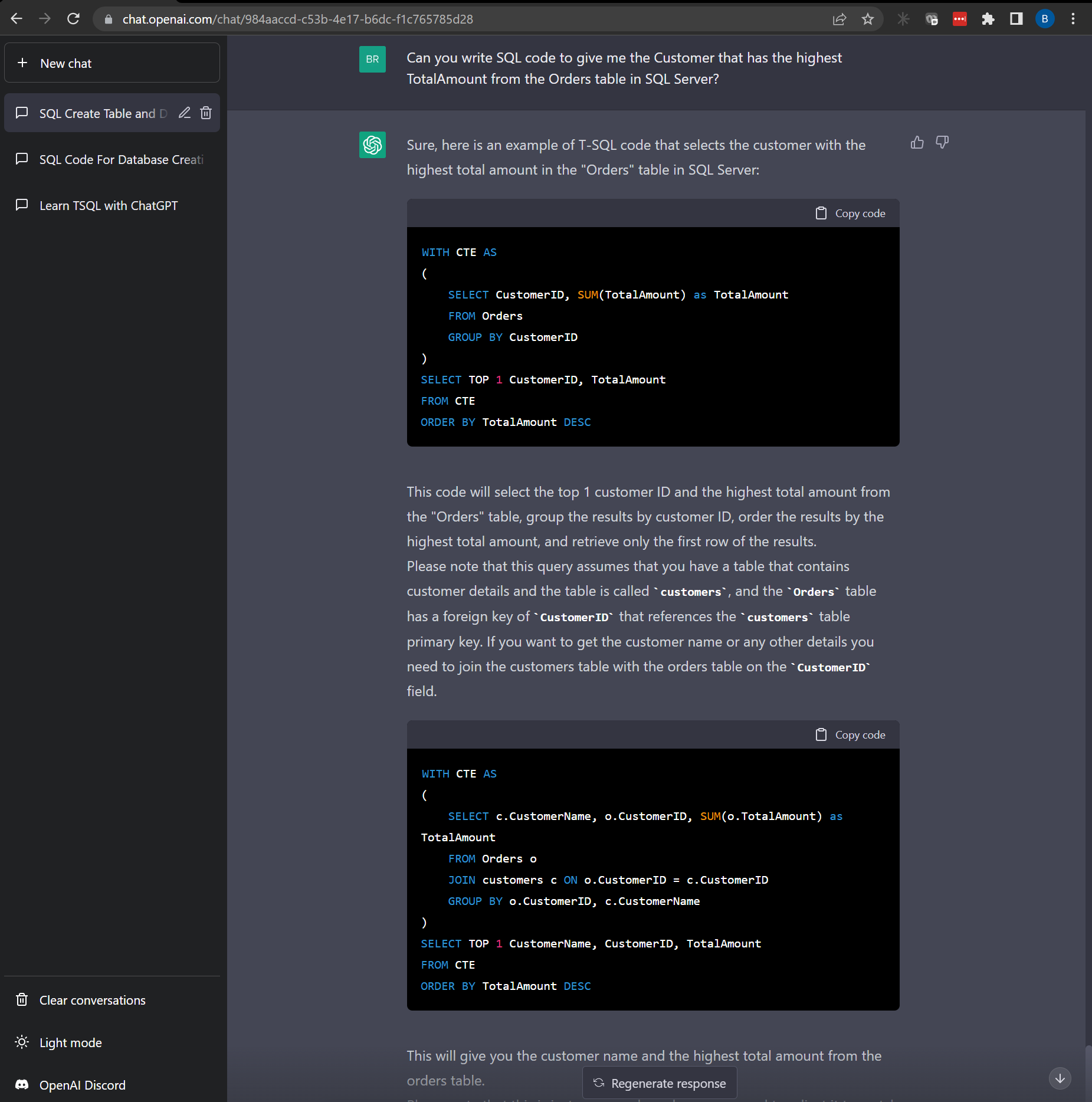
Again, not really what I was looking for, but it works. ChatGPT ended up writing more code than it needed and even wrote this statement in a common table expression (CTE). I was looking for something more along the lines of this:
SELECT TOP 1 CustomerID, MAX(TotalAmount) as MaxAmount
FROM Orders
GROUP BY CustomerID
ORDER BY MaxAmount DESC
Either way, both statements work and produce the same results.
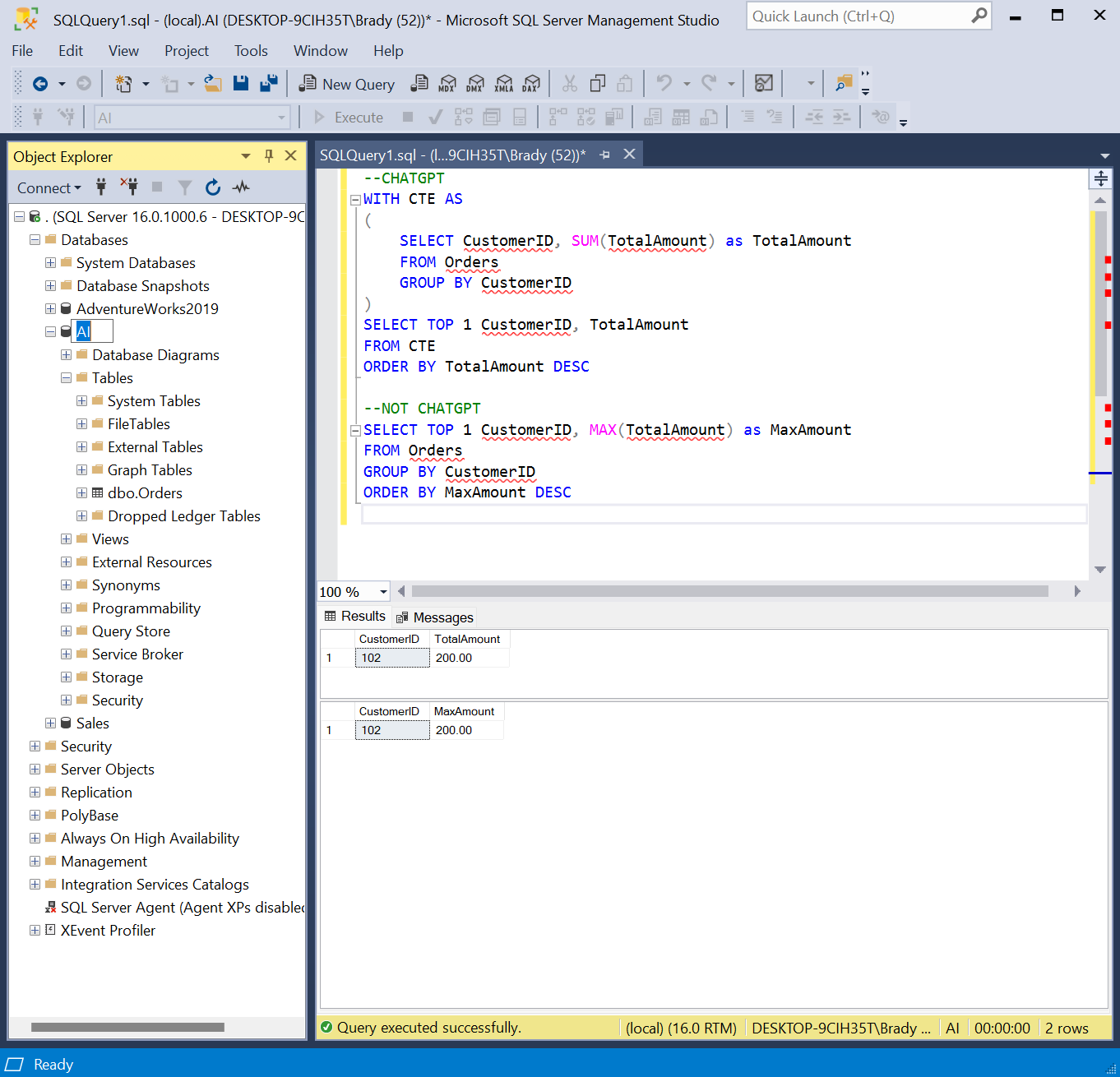
How about something a little more difficult such as creating a partition. Partitions are heavily used in other database platforms so I’m going to specify SQL Server again in this question.
“Can you write T-SQL code to partition my Orders table, OrderDate column by year on SQL Server?”
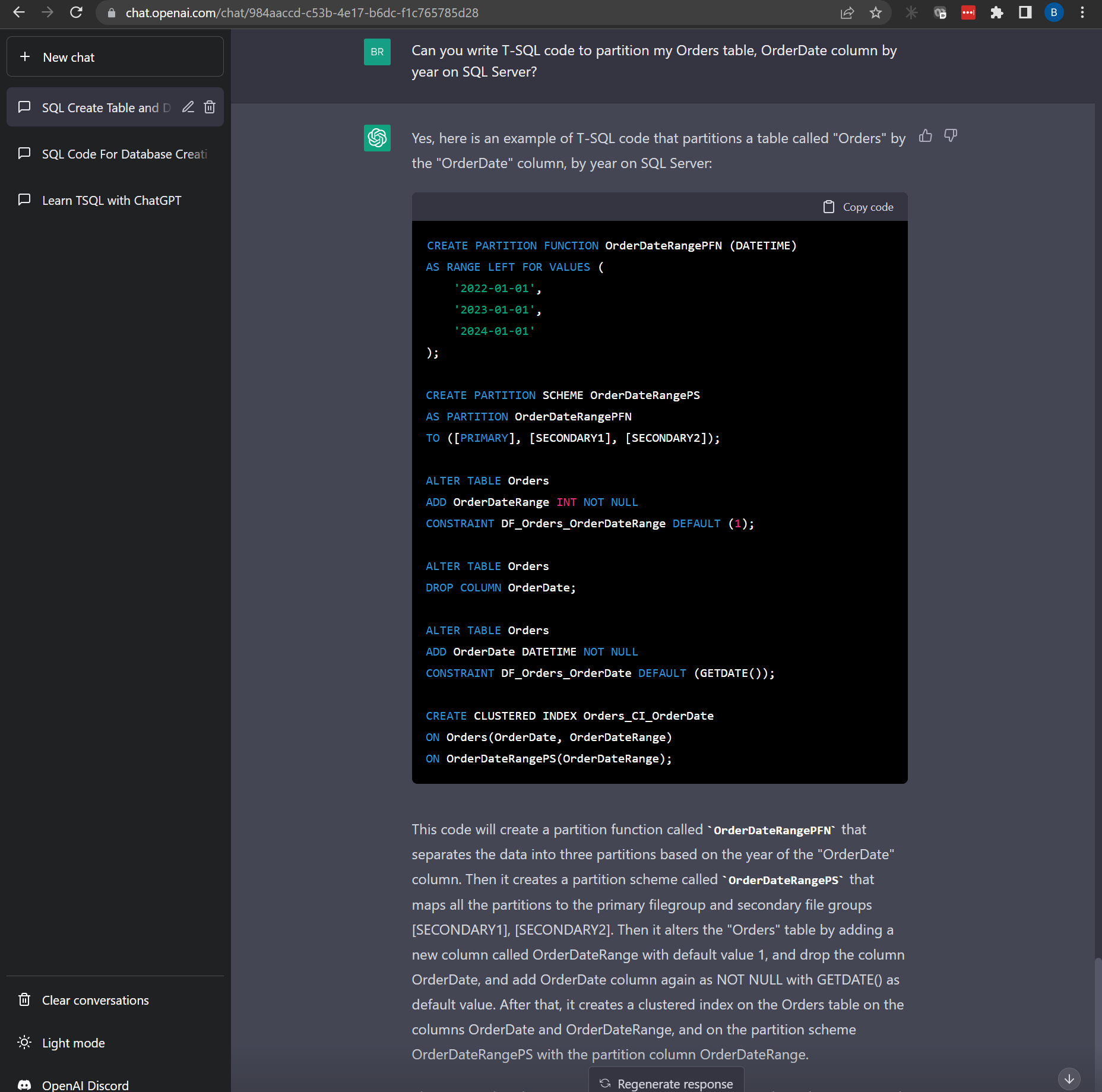
This was a little more challenging and it wrote out the Partition Function and Partition Scheme statements correctly, but it added a OrderDateRange column as an integer and then it tries to create a clustered index where OrderDate is datetime and OrderDateRange is int so the end result is a failure.
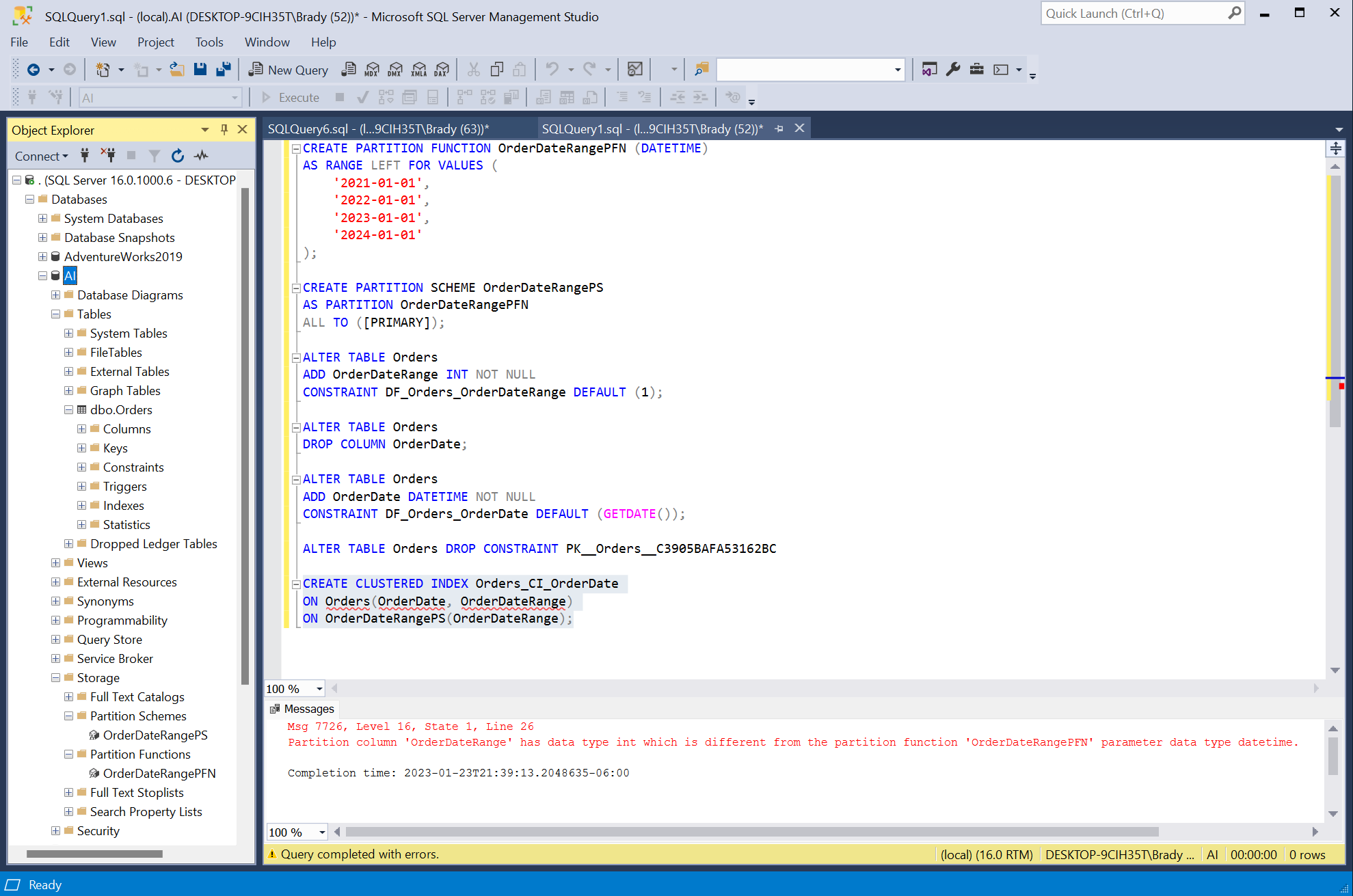
All in all, I think this is a great tool for learning basic (and even some advanced) SQL, but it still has some bugs to work out before it tries to replace me. 😉