In Part 1 we configured prerequisites for SQL Server 2012 new AlwaysOn and in Part 2 we’ll go over the fun stuff…configuring the High Availability Groups.
Create Sample Database and Create Backups
First thing we need to do is connect to the primary server using SSMS and create two databases and back them up to the network share we created. In this example I’ll create database RammerJammer and RollTide and then create database backups.
Specify Name
In SSMS go to Management, right click Availability Groups and click New Availability Group Wizard. Once the wizard appears click Next on the main screen and create a unique Availability Group name on the Specify Availability Group Name screen. I’ll name my group AG-Bama and then click Next.
Select Databases
On the next screen we will need to select our databases that we want added to our availability groups. This screen also has a status column that will let us know ahead of time if our databases meet the prerequisites. I’ll select both databases and click Next.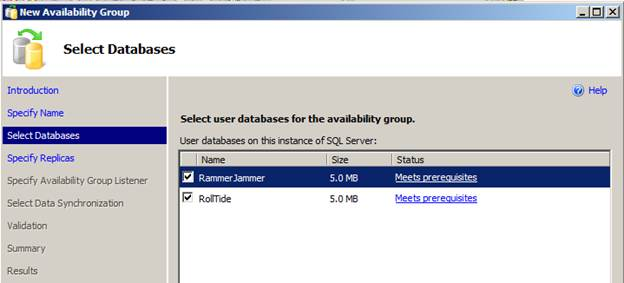
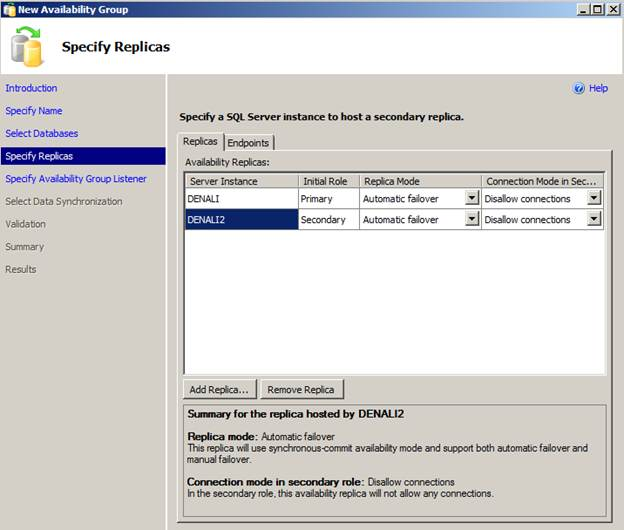
Specify Replicas
On the next screen click Add Replica… and connect to the other server (Denali2) Replica Mode can be set to Automatic Failover, High Performance, or High Safety.
- Automatic Failover: This replica will use synchronous-commit availability mode and support both automatic failover and manual failover.
- High Performance: This replica will use asynchronous-commit availability mode and support only forced failover (with possible data loss).
- High Safety: This replica will use synchronous-commit availability mode and support only manual failover.
Connection Mode in Secondary Role can be set to Disallow connections, Allow only read-intent connections, or Allow all connections.
- Disallow connections: This availability replica will not allow any connections.
- Allow only read-intent connections: This availability replica will only allow read-intent connections.
- Allow all connections: This availability replica will allow all connections for read access, including connections running with older clients. For this example, I’ll choose Automatic Failover and Disallow connections to my secondary role and click Next.
Click here to view the rest of this tip.